In their 2014 paper John Hull and Alan White derive generalized method for the construction of short rate trees. This generalization is interesting as it allows for one tree (or lattice) construction algorithm for all one factor short rate models. The only difference between the various models is the function 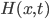 , which is explained briefly here and in detail in the paper. Continue reading
, which is explained briefly here and in detail in the paper. Continue reading

Here we share our current projects, research ideas, events, news and anything else that comes out of our brainstorming sessions
Compiling LevmarSharp (Visual Studio 2010)
Prerequisites:
-Visual Studio 2010
-levmar 2.6 (http://users.ics.forth.gr/~lourakis/levmar/)
-levmarsharp (https://github.com/AvengerDr/LevmarSharp)
For a recent research project we needed to solve an optimization problem. In specific we were trying to reproduce the results in the paper “A Generalized Procedure for Building Trees for the Short Rate and its Application to Determining Market Implied Volatility Functions” by Hull and White. In the paper it is described how a lattice can be constructed and calibrated to market. The calibration is essentially an optimization problem where the difference between the discount factors (or interest rates) observed in the market and the discounts generated in the model is made as small as possible by varying the model parameters.
Compiling Levmar using NMake (Visual Studio 2010)
Prerequisites:
-Visual Studio 2010 which comes with NMake
-levmar 2.6 (http://users.ics.forth.gr/~lourakis/levmar/)
For a recent research project we needed to solve an optimization problem. We considered using levmar by Lourakis. Not having touched C or build code using Make for a while it took a little while to get everything setup and building. In this blog the steps needed will be described. Should you run into trouble please consider the troubleshooting section at the end of this post. If you are interested in using levmar in C# check out this blog post.
Reproduction Example 1 of Generalized Procedure for Building Trees
In a recent (2014) paper John Hull and Alan White demonstrate a generalized method for the construction of short rate trees. Keen to understand the model we tried to reproduce the results of the first example mentioned in the paper on page 10. The example considers the short rate model:
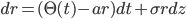
which is transformed using
Curiosities on the Monotone Preserving Cubic Spline
In this paper we describe some new features of the monotone-preserving cubic splines and the Hyman’s monotonicity constraint, that is implemented into various spline interpolation methods to ensure monotonicity. We find that, while the Hyman constraint is in general useful to enforce monotonicity, it can be safely omitted when the monotone-preserving cubic spline is considered. We also find that, when computing sensitivities, consistency requires making some specific assumptions about how to deal with non-differentiable locations, that become relevant for special values of the parameter space.
Keywords: Yield curve, fixed-income, interpolation, Hyman, monotone preserving cubic splines.
Click here for the full paper.
The Geometry of Interest Rate Risk
In this paper we consider the process of interest rate risk management. The yield curve construction is revisited and emphasis is given to aspects such as input instruments, bootstrap and interpolation. For various financial products we present new formulas that are crucial to define sensitivities to changes in the instruments and/or in the curve rates. Such sensitivities are exploited for hedging purposes. We construct the risk space, which eventually turns out to be a curve property, and show how to hedge any product or any portfolio of products in terms of the original curve instruments.
Keywords: Yield curve, hedging, interest rate risk management.
Click here for the full paper.
On the non-differentiability of Hyman Monotonicity constraint
In this paper we describe some new features of Hyman’s monotonicity constraint, which is implemented into various cubic spline interpolation methods. We consider the problem of understanding how sensitive such methods are to small changes of the input y-values and, in particular, how relevant Hyman’s constraint is with respect to such changes. We find that many things cancel out and that eventually Hyman’s constraint can be safely omitted when the monotone-preserving cubic spline is used. We also find that consistency requires including some specific boundary conditions that become relevant for special values of the parameter space.
Keywords: Yield curve, interpolation, monotone preserving cubic splines.
Click here for the full paper.
Finance: Between Testing and Regulations
Last July 8th we hosted our second meet up. The announced topics were Testing and Regulations, however the event was mostly testing. In a way, it has been very exciting to organise it, mainly because of some last-minute changes that affected the whole program. In fact, one of the speaker was sick and could not attend, and on top of that a few unexpected technical problems arose at the MixTup venue as well. Eventually everything worked fine and all the efforts made during the few days and hours before the event contributed to the success of the evening.
The chairman of the event was my colleague Jorrit-Jaap de Jong (Ugly Duckling), who entertained the audience, introduced the speakers, and reminded everybody of the purposes of the FEN evenings (which you can read in the ad of our introductory meeting here). The two talks were essentially on testing. The first speaker was our financial engineer Michele Maio (Ugly Duckling) who introduced various testing techniques and good practices such as test driven development and automated testing (mostly focusing on Excel and FitNesse). Michele used the programming language C#. The second speaker was Mert Aybat (Connectis). Mert had an extremely nice "live" and interactive presentation on how to use Mocks when testing complicated projects with many dependencies, and he definitely showed his competence in testing. Mert used Java and Mockito as tools of choice.
The crowd present to the meeting also deserves some comment. Besides the people who attended our first meeting, we were happy to see many new faces who joined this second event, coming both from the software and the finance industries. They all stimulated the discussions that arose during the presentations: thanks to them the flow of information was not in one direction only.
What will happen in the future?
It is important for us to keep track of what we want to achieve and what the FEN events are all about, namely: sharing knowledge, creating an intellectual stimulating environment, meeting like-minded people, discussing trends and hot topics in finance, and networking. In order to move forward, events are planned every couple of month, and the next one will be in autumn when everybody is back from summer vacations. We will keep the current format, which has been successful so far: hosting two talks within an informal environment with topics related to software, finance, and financial engineering.
Requests
To make the FEN community larger, it is crucial that everybody is active. That's why we would like to reminder everybody that anybody is welcome to join. Moreover, as Jorrit mentioned during this event:
- we are always looking for speakers, so if anybody is interested to talk at next event please let us know;
- we are also looking for locations, so if anybody would like to organise the next event with use by booking a seminar room in his/her bank or institution please let us know;
- we are always looking forward to growing our community, so please share it with your network.
Invite : Between Testing and Regulations
FEN Event - July 2014
Amsterdam - July 8 2014, 19:00 @ MixTup
Financial Engineering Netherlands (FEN) is a community of specialists in software and in the financial sector that everybody can join and consult.
The next FEN event will be held on July 8 and the topic will be about
"Finance Between Testing and Regulations".
The speakers for this evening are:
Paramita Banerjee (ING) **
Paramita is a business analyst at ING. Her predominant focus has been on operationlizing change solution within global investment banks normally representing AML and Front-Office interests, and her specialties are requirement elicitation and analysis and process modelling. She is an expert in the international banking and international finance sectors.
Mert Aybat (Connected Information Systems - Connectis)
Mert is a software engineer at Connectis. He has a strong quantitative (PhD in particle physics) background as well as an exhaustive international experience (he has lived and worked in many countries, such as US, Switzerland, Netherlands, etc.). His current work is in the area of information technology in general, and his specialty is information security.
The Talks
- Paramita Banerjee: Basel III on Stress Testing & Backtesting **
- Mert Aybat: Advanced Testing with Mocks: Theory and Practice
No prior knowledge of finance and/or financial engineering and/or testing will be required.
Registration
Via the Meet-up website. Please register asap.
If you have already registered but you are not able to come anymore, please let us know.
Space-time Coordinates
MixTup, Ferdinand Bolstraat 8, 1072 LJ Amsterdam (map). Doors open at 19:00.
Blog
Read here about how this event was.
---
** Paramita was sick during the actual event, so she could not attend. She was replaced by the Duckling Michele Maio (who also spoke at our opening event):
- Michele Maio: Automated Testing in Finance
---
Interpolation methods and the Hagan-West paper
Interpolation is a very useful technique for extracting data when the available information does not come in a continuous form.
From a non-technical point of view, any inference or decision process (sometimes subconsciously) is based on a kind of interpolation or best fitting or regression of the available informations. We as people are normally quite good at generalising (often too fast) from the little amount of information that we have about other people, situations, or even numerical data. This is possible because our brain can recognise patterns and see trends in any kind of data. However, technically speaking, interpolation is more that just finding a trend.
Technically, we are often given a discrete set of data corresponding to a certain function which is known at specific points, or nodes (for example, we have made an experiment for specific input values and measured the outputs corresponding to that input), and is otherwise unknown. In principle this is a multi-dimensional problem, and the interpolating hyper-surface will give an idea of the missing information. In fact, even if it is true that such a hyper-surface can always be numerically constructed, however the uniqueness issue remains. Given the same input data, many different constructions can be engineered, all satisfying to various -more or less realistic- criteria, and all passing through the same input points. Continue reading