Introduction
Standard fixed-income applications make a larger and larger use of the multi-curve framework to price products and hedge risks. For whatever reason this is the case, it is useful to know how to implement such a framework.
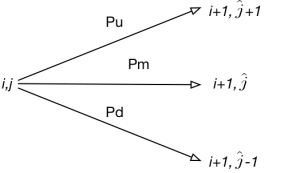
We have already talked about multi-curves in the past. Here we gave a list useful references and here we illustrated the mean features of risk metrics and sensitivity patterns. In this blog, we describe how to design the multi-curve framework. We do not claim that this is the only way or the best way. This is one possible way, which however turned out to work quite well within our system and happened to be easily integrated into our library.
Code snippets that will be shown below have been developed in C# using Visual Studio. Continue reading